3.1. “Players” instead of “Users”
What do I call those who interact with this music? For me, this question is more than a semantic sophistry, because it expresses my view of the relationship between the work and the recipient, who is also an active contributor here. The term “listener” is therefore directly excluded because of its passive nature. One can also listen “actively”, but this means rather a mental activity. There are several other possibilities:
“Dancers”
Many types of concerted movement patterns can be called dance, especially when they happen in conjunction with music (but also without it). Therefore the term “dancer” seems to be quite appropriate for someone who interacts with my music. The problem here is my presumed effect of this term. In the understanding of many people, “dance” has a narrower meaning and may be connected to specific situations, like dancing as a performance for others, dancing in a club etc. I am concerned that this word already evokes such ideas and contexts.
“Musicians”
Since using the software means triggering and influencing sounds, they could be simply called “musicians”. There are several arguments against this. For one thing, there is the problem of perception again. The term “musician” would certainly lead many to expect that a certain amount of practical experience and theoretical knowledge is necessary. On the other hand, actual musicians would most likely miss further possibilities and feel limited by the tool. Another argument is that making music is a controlling activity; but direct control is not the focus of this project.
“Users”
“Users” use a product or tool, mostly to solve a specific problem. In the case of music, one can think of “utility music”, such as Muzak or “elevator music”, which serves a very specific purpose (pleasant acoustic background, animation for consumption, etc.). Users have an idea of sovereignty over the tool. The relationship is asymmetrical and focused on an end result.
“Players”
The “player” is known in the digital world mainly from the field of “games”. Players interact with rule systems with the aim of making certain (especially emotional) experiences. The nature of this experience is made possible by the authors and producers of the games. Players are accustomed to engage with these virtual environments with a certain degree of openness, as long as they have the feeling that they participate in the success of the experience through relevant (inter)actions.
My decision: as long as someone navigates in the app’s interface, they are traditional “users”. When they enter the performance space, they are “players”.
3.2. Dynamic design parameters
3.2.1. Sound
“Sound” first of all describes everything that takes place acoustically “in the moment”. Music is then the artistic organization of sound. When I speak of sound as a creative parameter, I do not yet mean patterns of sounds in the form of a melody for instance, but rather the acoustic phenomenon in a relatively short time frame, in the range of milliseconds to a maximum of maybe a few seconds. With electronic sound generation, a general distinction must be made between real-time synthesis and sampling. The former offers more instantaneous design freedom, but this often requires more computing performance; after all, in the case of 16 bit stereo sound, the waves are computed 88.200 times per second. The sampling of already created or recorded sounds can be used here to create more complex sound designs. A third possibility is live input via microphones (e.g. vocals) or digital instruments. However, this input source is not used in this thesis.
In real-time synthesis, the parameters are first of all wave frequency and amplitude, as well as various properties that are responsible for the “timbre”, such as pitch, waveform, noise factor, harmonic structure, and their development over time. The “Volume” parameter is equally suitable for real-time synthesis as it is for samples. If only certain ranges are modulated in this way, it is called a filter: High-pass, low-pass and band filters. In this project I work with the following dynamic parameters:
- Pitch
- Amplitude
- Waveform
- Noise
3.2.2. Time / Rhythm
Another essential component of music is time. This does not mean the trivial fact that sound physically cannot take place without time, but time as a dimension of design with a significant structuring function. This takes place on numerous levels, from ADSR envelopes that modulate the amplitude/volume, through successive tones that can be perceived as melodies and rhythmic patterns, to the length of individual parts or pieces:
“Rhythm unfolds on multiple timescales, from the micro-rhythms of the waveform, to the undulations within a note, to the higher layers of phrases and macroform.” (Roads, 2015, p. 138) 22
Effects such as distortion or reverb are also based on the interaction of sound over time. Another factor that should not be underestimated is silence, the empty space between sound events.
Considering “beat”, one could naively come up with the approach to change the overall tempo of a piece, according to the speed of movement. I actually tried this out some time ago and it was very clear that this simple method does not work well because the player would get “out of step” frequently. One explanation for this is that the perception of “beat” does not only deal with the past and the current moment but is also a very old, intuitive way to look into the future, according to research in neurosciene:
“The manner in which people synchronize to the beat reveals that musical beat perception is a predictive process.” (Patel, Iversen, 2014) 23
Here, I open up the following design means to the input of the player:
- Distances within tone sequences of a fixed tempo
- Parameters of effects (e.g. reverb, bitcrusher or virtual guitar amp)
- Frequency of amplitude modulation through another oscillator
3.2.3. Larger compositional structures
esides these micro- and meso-parameters there are even larger structures. These range from the arrangement of smaller parts like phrases to the overall structure of the whole piece, considering prelude, choruses, breaks etc. As far as I can see, none of the works presented in 2.1. operates on this level. Very Nervous System seems to come closest, but Rokeby emphasizes that the virtual observer-musicians have quite a lot of autonomy and the actual influence of the player is limited.
“Each instrument is basically a behavior, an electronically constructed personality. It’s watching you. It’s looking out of the video camera at your body, and taking playing cues from your movement. These behaviors are just algorithmic definitions - computer subroutines. I construct them to suggest whether this instrument, for instance, tends to play on offbeats, or perhaps plays on offbeats but doubles its rhythm if you move faster. [...] Think of a jazz band: different players, each with his or her own style. In the case of Very Nervous System, these are the “behaviors,” defined by the software. Now give good jazz players some input - say, a chord chart or an old standard - and each player will improvise within his or her own style.” (Rokeby in an interview with WIRED magazine, 1995) 24
The interactive design of larger structures is also not part of this project. I think that the main challenge here is the following: These larger structures have a longer time frame, which means that it is not possible to react directly to momentary actions of the player, but that behavior has to be analyzed as a bigger picture. Using the research of Camurri et al, this would happen in levels three and four. Since music is a medium that has a strong emotional effect, this would mean translating the player’s movement expression into emotional qualities, and then countering this with musical expression. This seems to be a very difficult undertaking, which would probably have to work with rough generalizations.
I do not believe that good results are impossible here, and would like to try it, for example, in collaboration with experienced composers. However, such an undertaking goes beyond the scope of this project.
3.3. Processing data for musical feedback
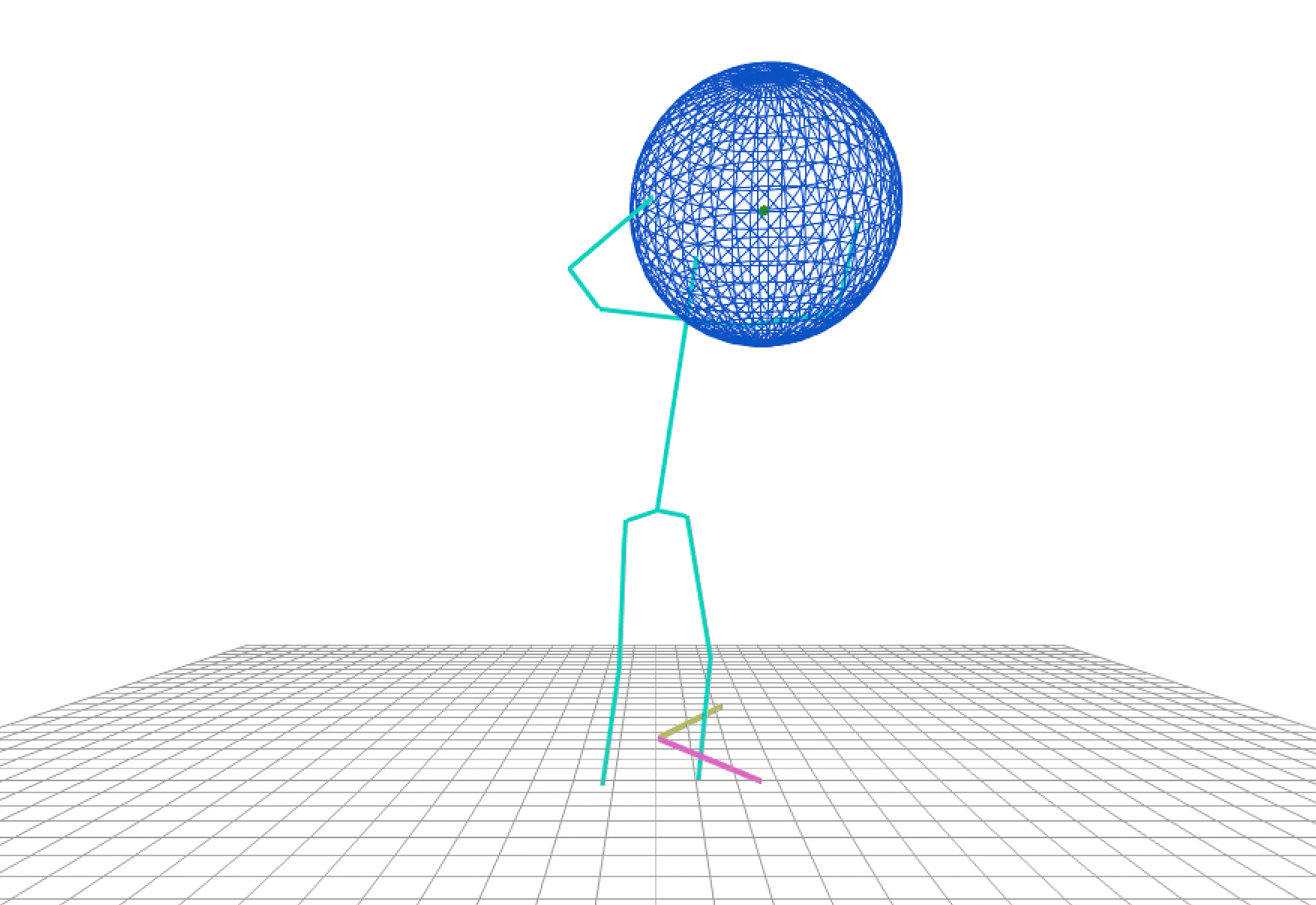
Figure 11. Early in the project I also experimented with virtual objects. The center of this virtual orb emits a pulsating sound which is manipulated according to the size and position of the sphere.Image: Weibezahn
3.3.1. Mappings
A relatively simple and basic method of translating information of various kinds into sound is to use mappings. This can also be used well for sonification. Here, an input parameter — this can be a color, a position, a speed and much more — is mapped to an output range that in some way influences the sound generation. A very simple variation would be to map the speed of a hand, i.e. the Euclidean distance from two successive positions, to the volume of the sound. Through the combination of several mappings, somewhat complex and interesting sound structures can already be created. In one experiment I multiplied the outputs of two oscillators, one generating the basic frequency (the pitch), the other oscillating at a much lower rate. The height of the basic frequency is based on the Y-rotation of the hip. The frequency of the low frequency oscillator is coupled to the movement of all limbs.
These mappings are also useful for influencing the playback of recordings. In one experiment I coupled the playback speed of the song “It’s Your Move”, in Diana Ross’ interpretation, to the intensity of the player’s movement. The song selection was not random: The cover version リ サフランク420 / 現代のコンピュー (Lisa Frank 420 / Modern Computing), by MacintoshPlus, which is a “classic” of the “Vaporwave” genre, is mainly based on sampling this song at reduced speed (including a lower pitch).
In principle, mappings are suitable for all effects and manipulations that are controlled by continuous parameters. I have further explored how players can intuitively and playfully “shape” the sound of an existing recording in real time through various body articulations. I use the term “shaping” because changing both the playback speed and the global pitch change make the sound appear as some kind of object with an invisible morphology. The source for this can be any recording as a flat digital file. I concentrated on vocal tracks of pop songs, especially to test the sonic effect of such a “shaping” on human singing. I tried to make the different input channels independent from each other so that they only interfere when the player wants to use more than one effect at a time. This avoidance of interdependencies should make the system flexible and open. The table below lists the parameters and the associated effects. I have documented this system in a video showing the interaction with the song “Halo” by the R’n’B and soul interpreter Beyonce.
The audio playback and manipulations are connected in this order one after the other:
Original Playback → Time & Pitch → Delay → Distortion → Reverb
This is based on the following consideration:
- For technical reasons, the pitch and tempo change must be applied directly to the original source
- The delay should be applied as directly as possible to the voice to make it sound like a “weird choir”
- The distortion should affect the entire sound before playback in this virtual space
- The reverberation should affect the entire output to create a virtual room whose size can be manipulated by the player
Where mappings have a continuous effect, triggers work discretely. An analogy from the world of physical instruments would be the striking of a string or the beating of a drum. Where this physical interaction is very direct, similar things in the virtual world require a high degree of mediation. The string to be struck is replaced by one or more threshold values, the transgression of which triggers the event, for example a boundary line in virtual space, or a deliberately set velocity value. Of course, in this case the triggered virtual object does not give any physical feedback like the bouncing off a drumhead.
Triggers are especially useful with position and speed data, as this can be understood by the player relatively easily. My goal is a playful interaction with as little initial cognitive load as possible; i.e. I want to avoid explanations. Therefore, in my opinion, reasonably direct triggers are most effective.
From a technical point of view, triggering can be a challenge for slow movements, because from a certain point, noise and error detection lead to false positives. According to research by Luke Dahl, “jerk” is the best value to trigger onsets 25, but I could not achieve reliable results due to the quality of the tracking. I use an “indirect” velocity value instead: if the position of a joint has shifted by a minimum distance after 5 frames, a triggering motion is recognized. This approach should reduce noise in the detection. The chosen number of 5 frames is a compromise between latency and noise reduction, which I have determined by subjective tests.
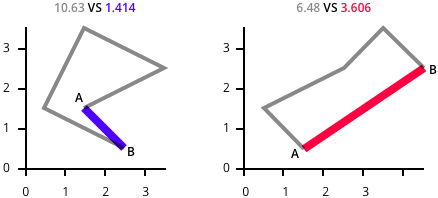
Figure 13. Illustration of detection logic. The combined length of the paths on the left is greater than on the right, but the path has less overall direction, which is inferred from the distance of the start and end points.Image: Weibezahn
3.3.3. Gestures and complex data collections
Gestures have discrete start and end points, and provide additional continuous data during execution. They can be used as spatial metaphors. On touch screens, the spreading of two fingers is a conventional gesture for enlarging the displayed content, such as a map section. In this project, one gesture could be a raising of both hands. Depending on the complexity of the movement pattern, gestures require a certain degree of learning and concentration on the users part.
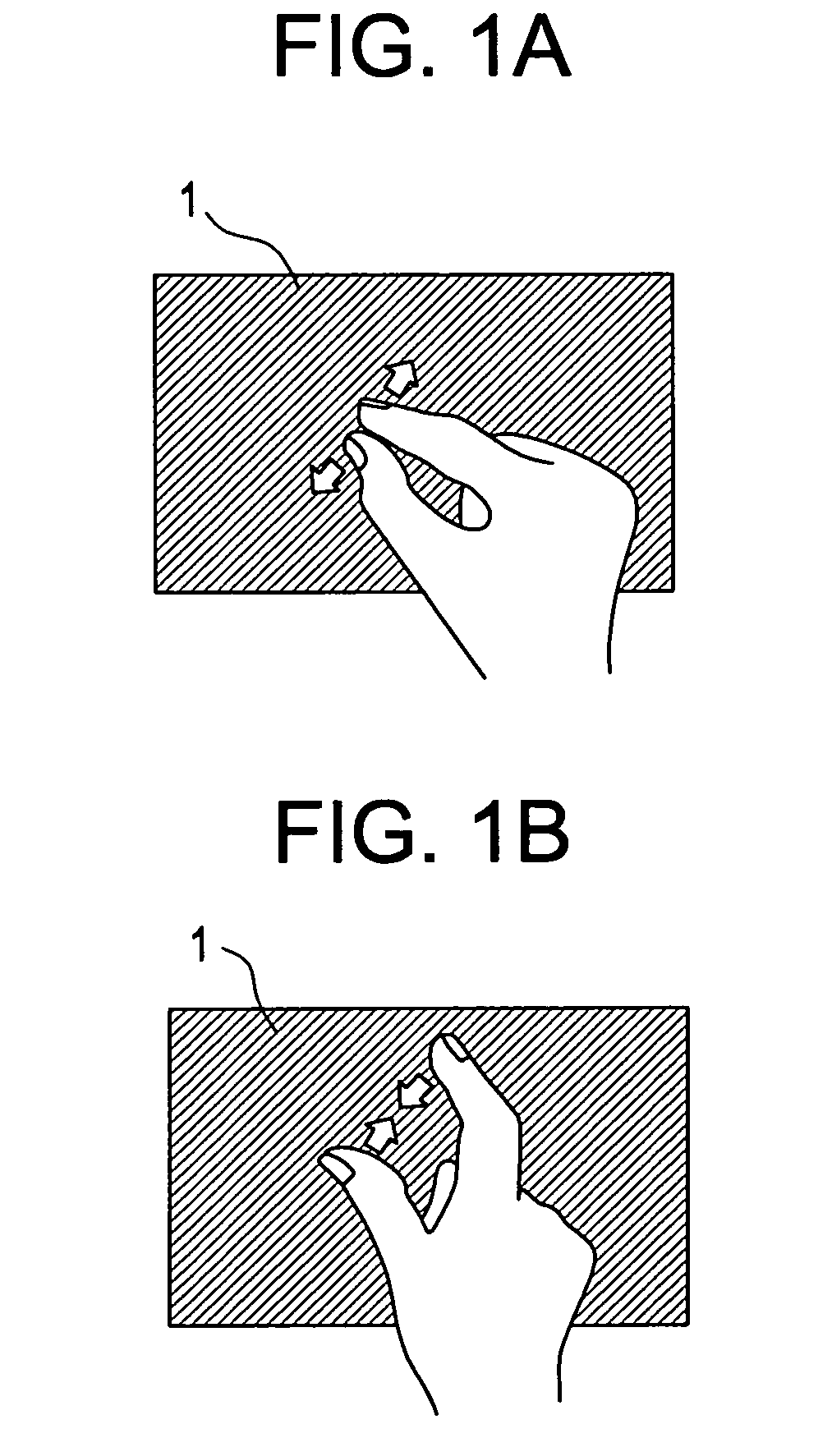
Figure 14. Drawing for a patent filing of the “Pinch to zoom” gesture.Image: Apple
Gesture detection is achieved through the interpretation of data bundles beyond single positions or simple relations. They often also include temporal information. The goal of the design of such data bundles is to filter information that says something about the behavior. There is a virtually unlimited number of them, and they can also take place on different levels of abstraction. Here are some that I tried out:
Rotation gesture
The Y-rotation of the player is calculated as the mean of the upper and lower body rotation, and the rotational speed is calculated from frame to frame. If a speed above a certain threshold is sustained for a number of frames, a “rotation” gesture is detected.
Path length
The accumulated distance that a joint has travelled over time. This length is suitable for determining speed over a longer period of time, for example to ensure that the intensity of movement remains at a certain level. Path lengths of several joints can also be added together to obtain an overview and identify dominant limbs.
Path Complexity
The ratio of Euclidean distance of start and end point of a joints path and its total length. 1 means lowest complexity; with more complexity, this value apporaches 0.
Contraction
The total distance of the joints to the barycentre of the body. A lower value means a more contracted posture. As a barycenter needs weight values, I used anthropometric research data from the US Aerospace Medical Research Laboratory. 26
Bounding Boxes
The surrounding box of multiple positions, in this case the historical positions of one or more joints, representing a point cloud. This box is a rough approximation of the volume. (A more accurate approximation would be a three-dimensional convex hull.) Besides the size of such boxes, their shape can be used as input. For individual joints, bounding boxes can only be created for historical position data. From at least three joints on, a momentary bounding box can be calculated. Here too, rough conclusions can be drawn from the ratio of the side lengths for the body articulation, the most simplest being how much space the player occupies. Another use case: if a joint moves primarily vertically, this can be determined by the aspect ratio of the box.
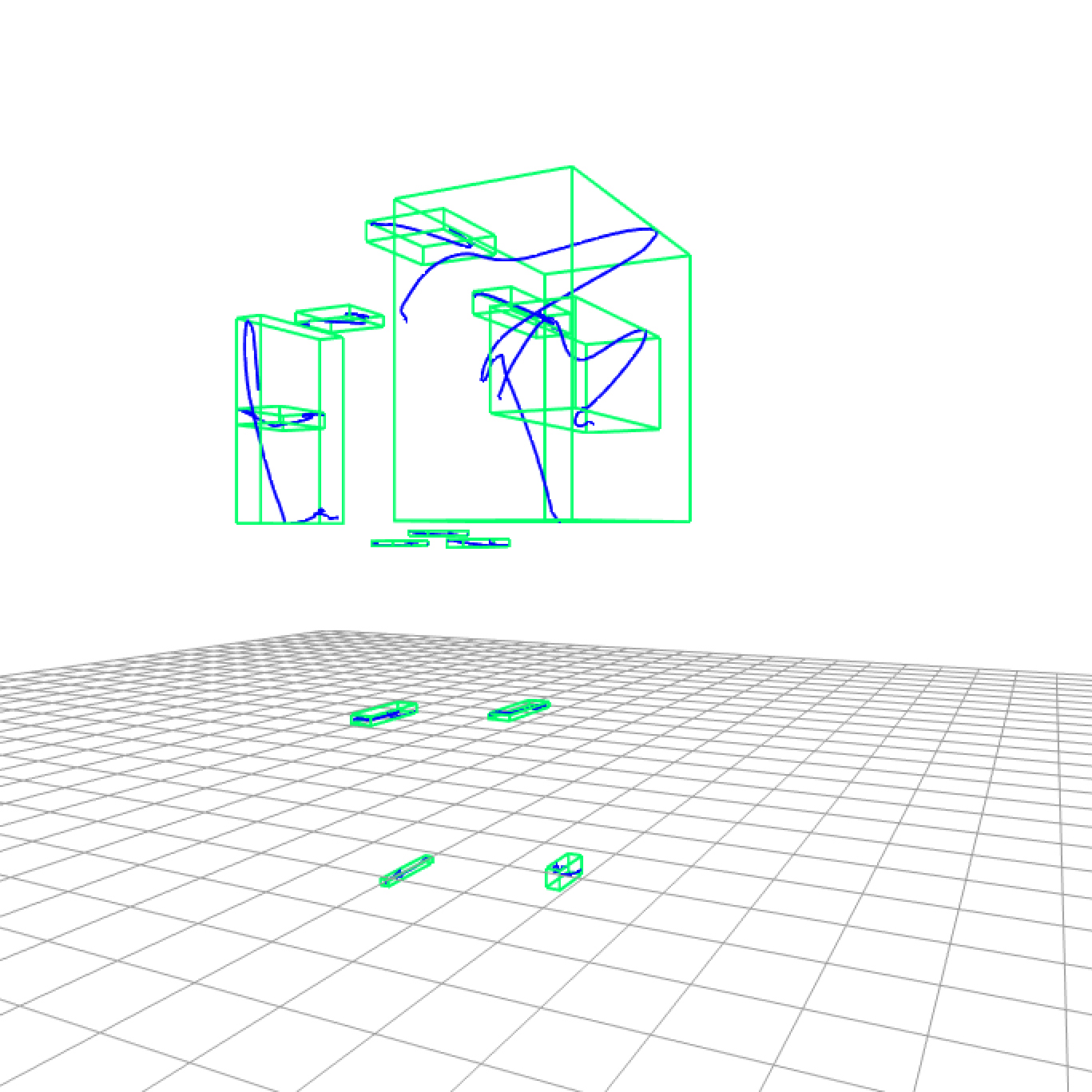
Figure 15. Bounding boxes of joint pathsImage: Weibezahn
Movement eccentric
This is an approach to find out how much players use different parts of their body, in different configurations. The idea is that if many motion paths intersect, the movement can be considered more “eccentric”. A rough approximation of this can be achieved by counting the intersections of the movement paths bounding boxes. This is a very indirect and rough parameter, but might be useful to alter a sonic texture or trigger probability based events (for example, in a rhythm-generating algorithm).
Hand dominance
People usually have a dominant hand that they use for activities like throwing etc. To “automatically” find the dominant hand of the player, I ask them at the beginning to raise one hand, but do not specify which one. I assume that they will raise their dominant hand. Later, I use this parameter for the mapping of harmony and melody.
This approach is inspired by computer games: In some first person shooters, players are asked to “look” up, down, left and right before they do anything else. This is used to determine if the camera control should be inverted.
3.4. Used interaction models
3.4.1. Joint-to-Pitch Method
This is one of the essential interaction models. The basic idea behind this method is to translate the position of a joint to a pitch. It is thus a mapping whose basic design parameters are the lower and upper limits of the input and output ranges. I use linear interpolation for that, but others are possible. Input and output can also be tit in a grid, for example, twelve semitones, or the notes of a scale for the output.
We are used to the relationship between pitch and physical space, either because of actual tonal effects (such as the length of a string) or practical, but ultimately arbitrary spatial arrangements, like the key arrangement on a piano. I use the Y-axis as a dimension for the input, since here the metaphor of “high” and “low” translates well to pitch.
Based on an already existing chord progression, I use the Joint to Pitch method to vary the chords and to generate melodies as follows.
Chord
The vertical position of a hand in a certain range (e.g. 0.5 m - 1.7 m) is mapped to a range of integers which denote octaves. When the chord is played, the notes are transposed accordingly by the selected octave (“octavated”).
Melody Note
First, a chord is selected as described above. Then the y-position of the hand is mapped inside the range for the resulting chord to an integer value between 0 to 2, representing the first note (“fundamental”), second note (“third”) and third note (“fifth”) of the chord.
I think that this basic method is suitable for further varying implementations. Thus one could perhaps use inversions instead of octavations of the whole chord to create a smooth transition. But I had no success with this so far judging from hearing the result; maybe this idea is too simplistic and thought from a technical perspective. I have presented a paper about this method, and the effects mapping method described in 3.3.1. as well, at the International Conference on Multimodal Interaction in October 2020. The paper has been published in the companion proceedings of the conference. 27
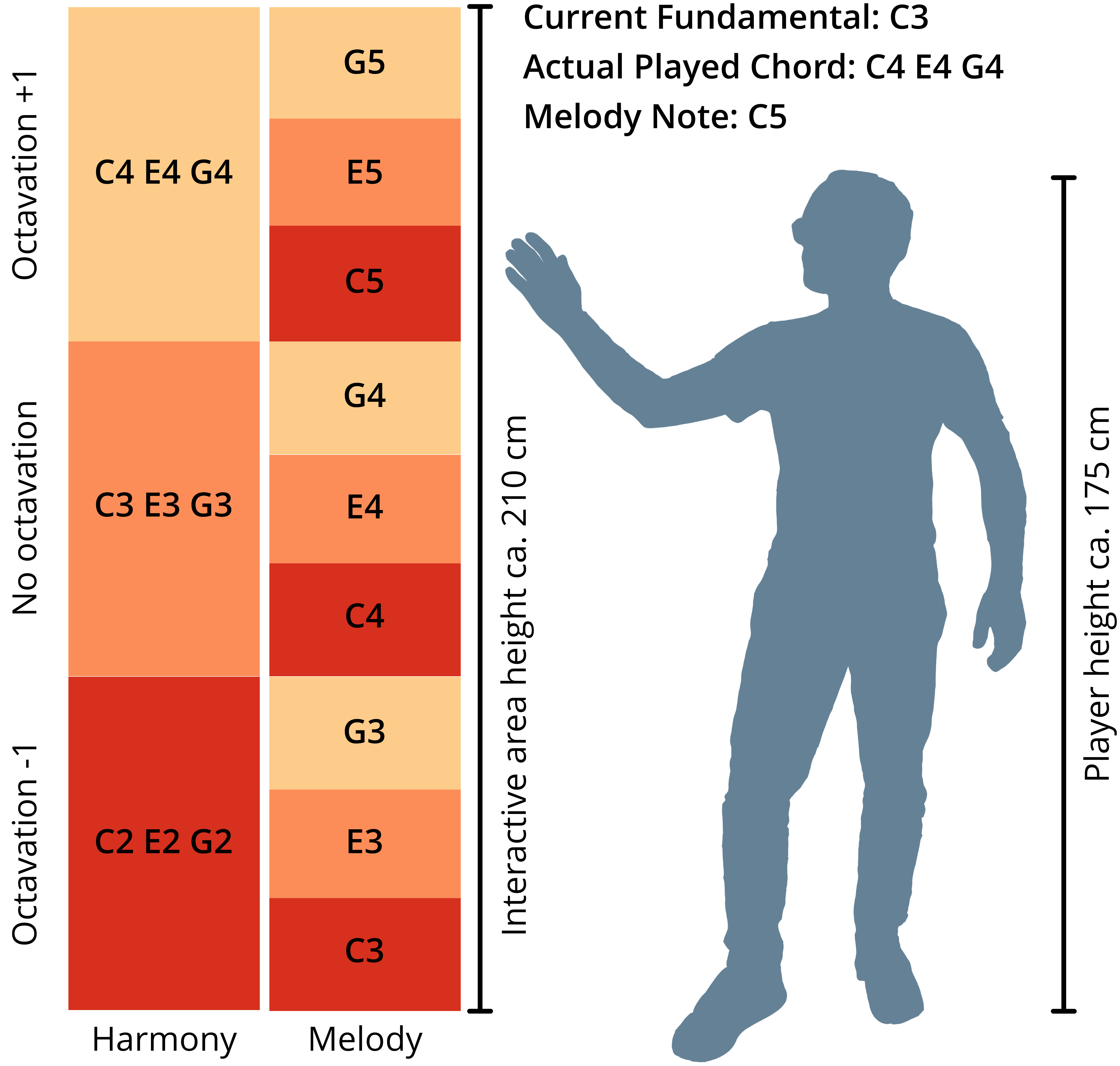
Figure 16. Example of the note selection in the Joint to Pitch method. In this case, the right hand controls the harmony as well as the melody. Additionally, the melody notes are transposed one octave further to diversify them from the harmony.Image: Weibezahn
3.4.2. Others
Activity Level
Besides the positions of the player’s limbs, the intensity of the movement is another important factor. To infer an “activity level”, I use two parameters:
- The speed of the joints
- The expansion in space
To evaluate the speed, I use the Euclidean distance between the current position of a joint and the position 20 frames prior, which is about half a second. I explicitly do not use the path length directly (the cummulated distances from frame to frame), because this value would be more distorted by the noise (see “Tracking Quality”). The expansion in space is calculated by the volume of the bounding box of the body. These values are combined to obtain an “activity level” and are used in several ways:
- The activity level of individual joints regulates the volume of instruments.
- The overall activity level can control additional effects and instrument layers, e.g. a distortion filter or the selection of drum patterns of different densities and speeds.
Whole body characteristics
This means the appearance of the body as a whole in the space, in shape and orientation. I do not use a structured model for this kind of input but try to provide somewhat meaningful reactions, e.g. shifting the waveform of an oscillator from a sine to a square for an unstable pose. Another expression could be a stretching of both arms towards the ceiling, or being very small (contracted). I use the data bundles mentioned in 3.3.3 in an experimental way for various feedback types.